
Une bonne indexation de votre site web est essentielle pour votre SEO, l’expérience des visiteurs et votre business de façon générale.
Mais ce n’est pas gagné d’avance : sans orientations précises, les crawlers (robots des moteurs de recherche) sont livrés à eux-mêmes et n’entreprennent pas forcément des actions à votre avantage.
Le fichier robots.txt est un outil essentiel pour avoir un contrôle sur l’exploration de votre site et inciter des actions qui favorisent votre référencement et votre activité.
Bien que la gestion d’un tel document puisse sembler challengeante à première vue, à la fin de la lecture de ce guide, vous aurez toutes les clés en main pour le faire d’une main de maître.
Hâte de vous donner plus de détails,
C’est parti.. !
Qu’est-ce que le robots.txt ?
Le fichier robots.txt, aussi appelé protocole d’exclusion des robots, joue un rôle clé dans la gestion de l’exploration de votre site web. Il sert à donner des consignes précises aux robots des moteurs de recherche sur les pages qu’ils peuvent consulter.
In short, il s’agit d’un simple fichier texte contenant des instructions destinées aux crawlers. Il leur indique quelles URLs ils peuvent ou ne peuvent pas visiter.
Ces règles s’expriment en autorisant « Allow » ou en interdisant « Disallow » le comportement de certains robots (ou de tous), selon les parties du site que vous souhaitez rendre accessibles et indexer.
Le robots.txt comment ça marche ?
Sur le Web, les robots sont en réalité des programmes automatisés qui parcourent les sites. En SEO, les plus connus sont ceux des moteurs de recherche comme Google, Bing, Yahoo ou encore Baidu. Leur mission ? Explorer les pages des sites pour les faire entrer dans l’index.
C’est grâce à cette indexation qu’elles peuvent apparaître – plus ou moins bien positionnées – selon les requêtes tapées par les internautes dans les moteurs.
Pendant leur exploration, les robots naviguent de lien en lien, sautant d’un site à l’autre comme d’un point A à un point B, puis à un point C, à travers des milliards de pages. Dès qu’ils arrivent sur un nouveau site, le premier “réflexe“ est toujours le même : chercher un fichier robots.txt.
S’ils en trouvent un, ils le lisent toujours avant de commencer à explorer – à la recherche d’instructions.
En revanche, s’il est absent ou mal configuré, le robot est censé parcourir tout le site sans restriction.
Exemple de fichier robots.txt
Le fichier peut sembler un peu technique à première vue, mais la syntaxe (codes du langage informatique) est très simple.
Vous pouvez attribuer des règles aux robots en précisant leur agent utilisateur (c’est-à-dire le robot concerné), suivi des directives.
Vous pouvez lui demander de visiter et faire indexer toutes les pages de votre site sauf un ou plusieurs répertoires spécifiques.
Et si vous souhaitez appliquer la même règle à tous les robots, il suffit d’utiliser le caractère générique astérisque (*). Ce symbole signifie que la directive concerne tous les agents utilisateurs, et pas un seul en particulier.
Par exemple, si vous souhaitez autoriser tous les robots, sauf celui de Yahoo, à parcourir votre site, voici à quoi cela ressemblerait :
💡 À noter : le fichier robots.txt donne des recommandations, mais ne peut pas les faire respecter de force. Les bons robots – comme ceux de Google – les suivent. Mais les robots malveillants (par exemple les bots de spam) peuvent tout simplement les ignorer.
Pourquoi le robots.txt est-il essentiel ?
Le fichier robots.txt permet de réguler l’activité des robots d’exploration. Il évite qu’ils surchargent votre site ou qu’ils indexent des pages non destinées au public.
Voici plusieurs raisons concrètes de l’utiliser :
Guider Google vers vos pages les plus importantes
Ce fichier vous aide à définir les pages que vous jugez prioritaires. Vous pouvez ainsi écarter les ressources secondaires de l’exploration, et concentrer les robots sur vos contenus les plus utiles comme vos pages de services, articles de blog ou fiches produits.
Il se peut que vous ne souhaitiez pas que Google indexe certaines ressources comme des PDF, des vidéos ou des images.
Peut-être voulez-vous garder ces fichiers privés, ou peut-être préférez-vous que Google se concentre sur des contenus plus pertinents.
Dans ce cas, le fichier robots.txt est votre meilleur allié pour empêcher leur indexation.
Optimiser le budget crawl
Le budget crawl correspond au nombre de pages que Google va parcourir sur votre site à un moment donné.
Ce chiffre dépend de plusieurs facteurs : la taille du site, sa santé, et les liens entrants (backlinks).
Si votre site contient trop de pages, Google risque de ne pas toutes les explorer.
Résultat : certaines pages ne seront pas indexées. Et si elles ne sont pas indexées, elles ne peuvent pas se positionner dans les résultats de recherche (pour aucun mot clé).
Rappelez-vous, sans fichier robots.txt, Googlebot est censé crawler tout votre site. Mais s’il consacre trop de temps à des pages peu importantes, vos contenus clés pourraient passer à la trappe.
En bloquant les Urls à faible valeur ajoutée, vous permettez à Googlebot de consacrer une plus grande partie de votre budget d’exploration aux pages qui comptent.
De ce fait, vous augmentez vos chances d’être bien référencé.
Bloquer les pages dupliquées ou privées
Toutes les pages de votre site n’ont pas besoin d’être explorées ou visibles dans Google.
Par exemple :
- une version staging de votre site
- les pages de résultats de recherche internes
- les doublons
- les pages de connexion
WordPress bloque d’ailleurs automatiquement /wp-admin/ à tous les robots d’exploration.
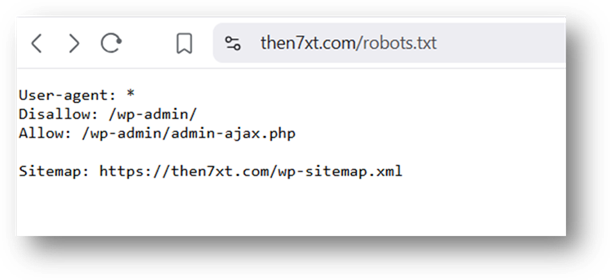
Image : Version initiale de notre robots.txt (le site N7XT est sur WordPress)..
Ces pages doivent exister, mais elles n’ont pas besoin d’apparaître dans les moteurs de recherche. Le fichier robots.txt vous permet donc de les bloquer facilement aux robots.
Syntaxe Robots.txt : Langage des fichiers robots.txt
Un fichier robots.txt suit une structure très basique :
- Un ou plusieurs blocs de règles (ou directives),
- Chaque bloc commence par un User-agent spécifié,
- Suivi d’une ou plusieurs instructions Allow ou Disallow.
Voici un exemple de bloc simple :
C’est quoi un User-agent (ou agent utilisateur) : * ?
Le terme « User-agent » fait référence aux robots des moteurs de recherche. C’est à eux que s’adressent les directives du fichier.
La directive User-agent
Chaque bloc débute toujours par la ligne User-agent. Elle permet d’indiquer à quel robot s’adresse la règle.
Par exemple, pour dire à Googlebot de ne pas explorer la page d’administration de votre site WordPress, vous écrirez :

📌 À noter : un même moteur de recherche utilise souvent plusieurs robots (pour l’index classique, les images, les vidéos, etc.).
Il choisit toujours le bloc de directives le plus précis qu’il peut trouver.
Supposons que vous ayez trois ensembles de directives : un pour *, un pour Googlebot, et un pour Googlebot-Image.
Si l’agent utilisateur Googlebot-News parcourt votre site, il suivra les directives Googlebot.
En revanche, l’agent utilisateur Googlebot-Image suivra les directives plus spécifiques de Googlebot-Image.
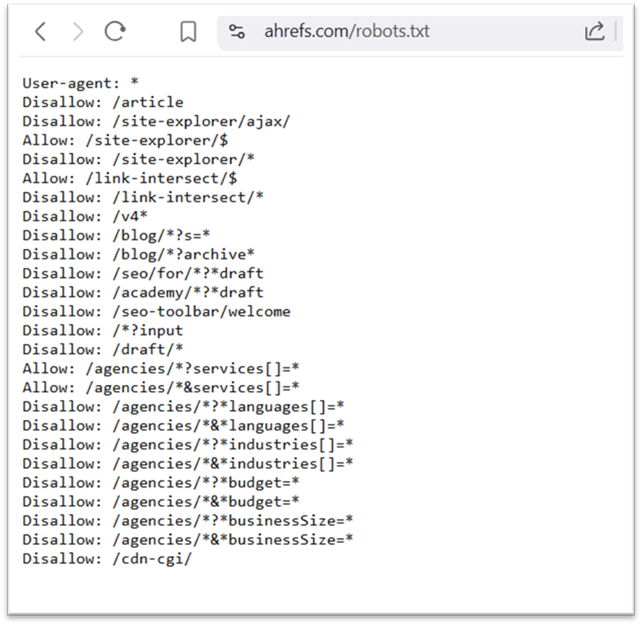
Voici une petite liste de robots d’exploration du Web et de leurs différents agents utilisateurs… :
📌 À noter : un même moteur de recherche utilise souvent plusieurs robots (pour l’index classique, les images, les vidéos, etc.).
Il choisit toujours le bloc de directives le plus précis qu’il peut trouver.
Par exemple :
- Si vous avez une règle pour *, une pour Googlebot, et une autre pour Googlebot-Image,
- Alors Googlebot-News suivra les règles de Googlebot,
- Tandis que Googlebot-Image appliquera celles qui lui sont dédiées.
Voici une petite liste des robots d’exploration et de leurs User-agents :
La directive Disallow
Juste après le User-agent, vient la directive Disallow.
Elle sert à préciser les parties du site à ne pas explorer.
Vous pouvez ajouter plusieurs lignes Disallow pour bloquer plusieurs sections.
✔️ Une ligne Disallow vide signifie que rien n’est interdit. Le robot peut donc accéder à toutes vos pages.
Comment fonctionnent la commande Disallow dans un fichier robots.txt ?
Masquer l’ensemble du site web des bots
- Pour empêcher tous les moteurs d’explorer votre site (quoi que ce soit) :

Autoriser un accès complet
- Tandis que pour autoriser tous les moteurs à explorer tout votre site, le bloc ressemblera à ceci :

Mais la directive Allow, on y revient plus tard..
Bloquer un répertoire entier
Pour empêcher l’accès à tout le répertoire /blog, vous pouvez utiliser la directive suivante :

Bloquer un fichier spécifique
Par exemple, si vous souhaitez bloquer une page de blog en particulier… :

📝Les directives Allow et Disallow ne sont pas sensibles à la casse, vous pouvez donc les écrire en majuscules ou non.
Mais les chemins spécifiés le sont.
Par exemple : /album/ ≠ /Album/ …
Il faut savoir qu’il existe des caractères génériques dans robots.txt
- * (astérisque) : il représente n’importe quel robot. C’est ce qu’on appelle une « wildcard ».
- / : il désigne toutes les pages et répertoires du site.
Exemple :

Cela interdit l’exploration de tout le site par tous les robots.
Maintenant que tu connais les règles de base, on peut passer aux règles un peu plus avancées.
Quelles autres commandes apparaissent dans un protocole d’exclusion des robots ?
La directive Allow
La directive Allow fonctionne à l’inverse de Disallow. Elle permet à un moteur de recherche d’explorer une page ou un sous-dossier précis même si le répertoire principal est bloqué.
Pour en revenir à l’exemple plus haut, si vous souhaitez empêcher Googlebot d’accéder à tous les articles de votre blog, sauf un, votre fichier pourrait ressembler à ceci :

À noter : tous les moteurs de recherche ne prennent pas en charge cette commande. Google et Bing oui.
La directive Sitemap : qu’est-ce que le protocole Sitemaps et pourquoi est-il inclus dans robots.txt ?
La commande Sitemap permet d’indiquer aux robots l’emplacement de votre sitemap XML.
Les sitemaps listent généralement les pages que vous souhaitez faire explorer et indexer par les moteurs de recherche.
Cette directive peut se placer en haut ou en bas du fichier robots.txt.
Ce n’est pas obligatoire, mais si vous pouvez aussi utiliser votre fichier robots.txt afin de mener les moteurs de recherche au sitemap de votre site, autant en profiter.
La plupart des moteurs comme Google, Bing ou Yahoo le prennent en charge.
Cela les aidera à mieux comprendre l’arborescence de votre site.
Cela dit, il est également conseillé de soumettre votre sitemap XML directement via les outils pour webmasters du moteur.
Les robots finiront par explorer votre site, mais cette soumission accélère le processus.
La directive Crawl-delay
La directive Crawl-delay définit un délai d’attente (en secondes) entre chaque action d’un robot sur votre site.
Elle sert à éviter que les robots ne surchargent le serveur et ralentissent votre site.
⚠️ Google ne prend plus en compte cette directive. Si vous voulez ajuster la vitesse d’exploration de Googlebot, vous devez le faire via la Search Console.
En revanche, Bing et Yandex la supportent encore.
Voici un exemple pour demander aux robots d’attendre 20 secondes entre chaque action d’exploration :

La directive Noindex
Le fichier robots.txt sert à dire aux robots ce qu’ils peuvent ou non explorer, ce qui n’est pas une indication à indexer (ou pas) une URL.
La page peut quand même apparaître dans Google (les résultats de recherche), mais sans que le robot sache ce qu’elle contient.
In short, pour empêcher de manière fiable l’affichage d’une page dans les résultats, utilisez la balise meta robots noindex..
Comment trouver un fichier Robots.txt (Où mettre le robots.txt ?) ?
Le fichier robots.txt se trouve sur le serveur de votre site, au même titre que les autres fichiers.
Pour le consulter, il suffit d’ajouter /robots.txt à la fin du nom de domaine.
Par exemple : https://then7xt.com/robots.txt. Ceci est valable pour tous les sites web.
Important : le fichier doit toujours se situer à la racine du domaine.
Pour un site : mondomaine.com, le robots.txt doit se situer à https://mondomaine.com/robots.txt.
S’il se trouve ailleurs (ex. https://mondomaine.com/pages-importantes/robots.txt), les robots considéreront qu’il n’existe pas.
Voyons en détails, comment créer un robots.txt…
Comment créer un fichier robots.txt pour votre site web
Si votre site n’a pas encore de fichier robots.txt, pas de panique. Vous pouvez le créer vous-même ou utiliser un générateur de fichiers robots.txt.
Créez un fichier texte nommé robots.txt
Commencez par ouvrir un nouveau fichier texte avec un éditeur basique.
Pas besoin de logiciel compliqué : Bloc-notes (Windows) ou TextEdit (macOS) suffisent largement.
Ensuite, nommez ce fichier robots.txt (obligatoirement).
Une fois que c’est fait, vous pouvez commencer à saisir vos directives.
⚠️ Attention : n’utilisez pas un traitement de texte pour la création du fichier. Ils enregistrent le fichier dans un format propriétaire, ce qui peut ajouter des caractères et poser problème.
Ajoutez les règles à suivre par les robots
Un fichier robots.txt contient un ou plusieurs groupes de directives.
Chaque groupe commence par un User-agent (le robot visé), suivi de lignes d’instructions :
- les répertoires ou pages interdits
- ceux autorisés
- et éventuellement le sitemap du site
Les robots ignorent tout ce qui ne correspond pas à une de ces directives.
Exemple : vous ne voulez pas que Google explore le dossier /clients/ réservé à un usage interne.
Votre bloc ressemblerait à ceci :

Si vous souhaitez lui bloquer un autre dossier aussi, il suffit d’ajouter une ligne :

Puis, pour passer à un nouveau groupe de règles (pour les autres robots, peut-être) :
Tapez deux fois la touche Entrer, et poursuivez…

Celui-ci empêche tous les moteurs de recherche d’explorer vos répertoires /archive/ et /support/ qui disons sont réservés à un usage interne.
Enfin, vous pouvez indiquer l’URL de votre sitemap à la fin :

Voici à quoi peut ressembler votre fichier robots.txt de deux groupes de directives et un sitemap bien placé à la fin :

En noir peut-être.. 🙂
Pensez bien à enregistrer votre fichier sous le nom exact : robots.txt (en minuscules, sans majuscule ni extension supplémentaire).
📌 Important : Les robots lisent le fichier de haut en bas et appliquent le premier groupe de règles le plus spécifique.
Commencez donc par les règles spécifiques (comme Googlebot) avant celles générales (*).
Téléversez le fichier robots.txt à la racine de votre site
Une fois votre fichier prêt, il faut le mettre en ligne pour qu’il soit accessible aux moteurs de recherche.
Malheureusement, il n’existe pas de méthode unique pour cette étape. Tout dépend de la structure des fichiers de votre site et de l’hébergeur.
Faites une recherche rapide en ligne ou contactez votre hébergeur pour savoir comment procéder.
Par exemple, tapez « téléverser un fichier robots.txt sur WordPress ». Vous pourrez même accéder à une documentation de votre Hébergeur (Hostinger etc.) ou CMS.
📍 Il doit être placé à la racine du site vous vous rappelez ? C’est-à-dire ici :
https://votresite.com/robots.txt
Une fois en ligne, testez-le. Vérifiez qu’il est accessible publiquement et que Google peut le lire.
Voici comment faire..
Testez et vérifiez l’implémentation de votre fichier robots.txt
Avant toute chose, assurez-vous que votre fichier robots.txt est bien accessible en ligne.
Pour cela, ouvrez une fenêtre de navigation privée et entrez l’URL complète de votre fichier : https://votresite.com/robots.txt.
Si le fichier s’affiche avec les directives que vous avez ajoutées, vous pouvez passer à l’étape suivante : le test du balisage.
Deux options s’offrent à vous pour tester ce fichier :
- L’outil de test de Google Search Console
- La bibliothèque open source robots.txt de Google (plus technique)
Voici comment procéder dans la Search Console :
- Connectez-vous à votre compte Search Console.
- Accédez au testeur de fichier robots.txt.
- Cliquez sur « Ouvrir l’outil de test du fichier robots.txt ».
Si votre site n’est pas encore relié à votre compte Search Console, ajoutez une propriété, puis vérifiez que vous en êtes bien le propriétaire.
Si vous avez déjà des propriétés vérifiées dans la Search Console, sélectionnez simplement celle qui vous intéresse dans le menu déroulant de l’outil – en page d’accueil.
Google analysera automatiquement votre fichier.
Il vous signalera toute erreur de syntaxe ou incohérence logique.
Vous verrez le nombre d’erreurs ou d’avertissements affiché juste sous l’éditeur.
Vous pouvez corriger directement dans l’interface, puis relancer le test autant de fois que nécessaire.
⚠️ Attention : les changements effectués dans l’outil ne sont pas enregistrés sur votre site. Il s’agit d’une version test uniquement. Pour appliquer vos corrections, copiez simplement le contenu corrigé et remplacez le fichier robots.txt en ligne.
Robots.txt : les bonnes pratiques
En langage informatique, une erreur est vite arrivée. Gardez ces bonnes pratiques à l’esprit en créant votre fichier robots.txt, pour éviter les plus courantes.
Mettez chaque directive sur une ligne séparée
Chaque directive doit avoir sa propre ligne. Sinon, les robots ne comprendront pas vos instructions.
A ne pas faire :

Utilisation correcte :

Ordre de préséance
Chaque moteur de recherche lit le fichier robots.txt à sa manière.
Par défaut, c’est souvent la première directive qui prévaut.
Mais chez Google et Bing, les instructions les plus ciblées (spécifiques à un user-agent) importent plus.
Ne mentionnez un agent utilisateur qu’une seule fois
Même si les robots peuvent lire un fichier avec le même User-agent mentionné plusieurs fois, il vaut mieux le mentionner une seule fois.
Cela évite les doublons et réduit les risques d’erreur.
Mauvaise pratique :

Bonne pratique :

Google comprendra les deux dans tous les cas, mais la deuxième version est plus propre et plus claire.
Utilisez l’astérisque (*) pour simplifier vos règles
L’astérisque (*) permet d’appliquer une règle à tous les robots, ou de cibler plusieurs URL.
❌ Par exemple, au lieu de bloquer les URL contenant des paramètres individuellement :
✅ Faites plus simple et efficace…

Ce format bloque toutes les Urls dans le sous-dossier /shoes/ et contenant un point d’interrogation.
Servez-vous de « $ » pour indiquer la fin d’une URL
Le signe « $ » permet d’indiquer la fin d’une URL.
Par exemple, si vous voulez bloquer l’exploration de toutes les images .jpg sur votre site, vous pouvez les lister une à une…
❌ Mauvais exemple :

✅ Ou… :

Dans cet exemple, /chien.jpg ne pourra pas être exploré, mais /chien.jpg?p=32414 oui, car il ne se termine pas par « .jpg ».
👉 Le « $ » est très utile. Mais attention : mal utilisé, il peut débloquer plus que prévu. A utiliser avec prudence donc…
Ajouter des commentaires avec le symbole
Les robots ne considèrent pas les lignes qui commencent par un dièse (#).
Les développeurs s’en servent donc pour insérer des commentaires dans le fichier robots.txt. C’est pratique pour garder le fichier clair, organisé et facile à lire.
Pour ajouter un commentaire, il suffit de commencer votre ligne par un #, comme ici :

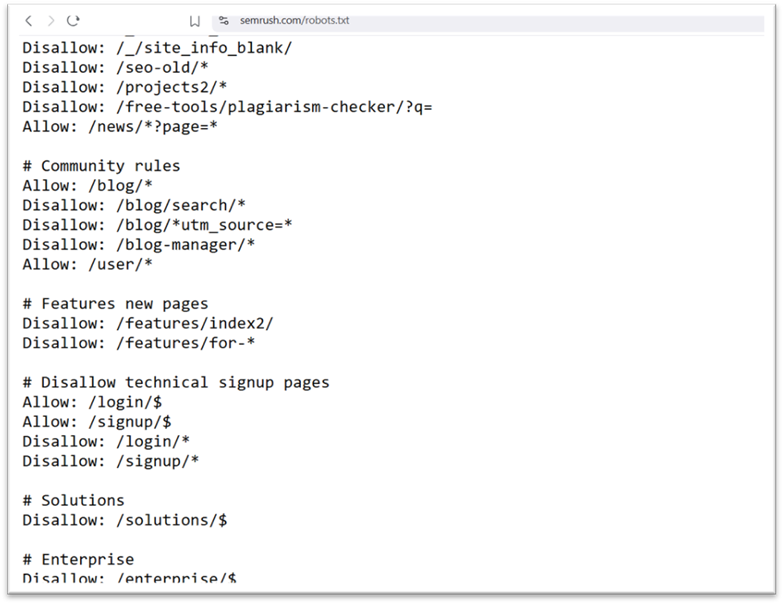
Vous trouvez de bons exemples de son application dans le robots.txt de SemRush…
Certains développeurs s’en servent même pour glisser des messages amusants, sachant que peu de gens s’aventurent sur cette page.
Vous connaissez peut-être le fameux « just crawl it » de Nike, une référence à leur slogan « just do it »,
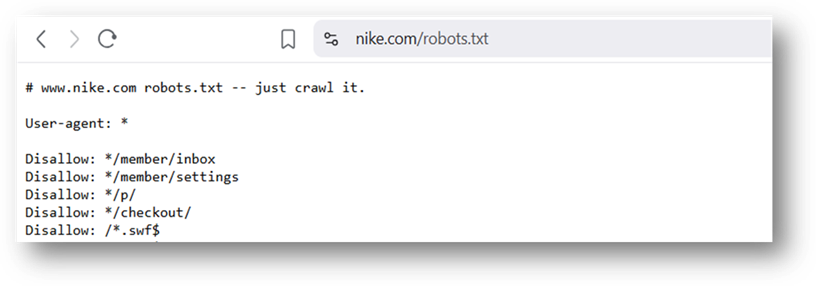
Accompagné d’une représentation de leur logo..
« Just crawl it »… bien vu ça, non ? Haha..
Un fichier robots.txt par sous-domaine
Le fichier robots.txt ne s’applique qu’à l’hôte où le fichier est hébergé.
Si vous voulez contrôler l’exploration d’un sous-domaine de votre propre domaine, vous devez créer un fichier robots.txt distinct.
Par exemple,
Si votre site principal est sur domaine.com et votre blog sur blog.domaine.com (sous-domaine), vous devrez créer deux fichiers robots.txt distincts.
Un pour le répertoire racine de votre domaine principal et un autre pour le répertoire racine de votre blog.
La règle : un fichier robots.txt par domaine (et sous-domaine)..
Méfiez-vous des robots malveillants
Le fichier robots.txt n’est qu’une indication de conduite pour les crawlers.
Les moteurs de recherche sérieux (comme Google) la respecteront certainement.
Mais certains robots malveillants, eux, ignorent totalement les règles.
Ils peuvent explorer les pages que vous avez pourtant interdites.
Autrement dit, ce fichier ne protège pas votre site contre les robots malintentionnés. Il faut donc le combiner à d’autres mesures de sécurité si besoin.





