
Qu’est-ce que Googlebot ?
Googlebot est le programme principal que Google utilise pour découvrir et explorer automatiquement des pages web.
Il visite les pages web et collecte des informations qui permettent à Google de comprendre ce qu’elles contiennent.
On l’appelle crawler, robot ou encore spider (araignée, en français). C’est tout simplement un des agents « client » déployé par Google pour exécuter des actions précises, en l’occurrence le scannage de sites web.
Le rôle du Spider SEO de Google
En tant que principal robot d’exploration de sites web, le rôle de Googlebot est de maintenir à jour l’immense base de données de Google, appelée l’index.
Plus cet index est complet et actualisé, plus les résultats affichés dans la recherche seront pertinents et utiles pour les internautes.
Sous-types Googlebot :
Il existe en réalité deux principaux types de robots d’exploration utilisés par la recherche Google, et généralement appelés Googlebot :
- Googlebot Smartphone : il simule la navigation d’un utilisateur sur un appareil mobile.
- Googlebot Desktop : il se comporte comme un utilisateur sur ordinateur et analyse la version bureau du site.
Astuce pro : pour savoir quel type de Googlebot a visité votre site, consultez l’en-tête de requête HTTP user-agent dans la requête. Mais attention : les deux robots utilisent le même jeton user-agent dans le fichier robots.txt, ce qui rend impossible d’identifier le type de robot à partir de ce fichier seul.
Notez qu’il existe aussi des robots d’exploration plus spécialisés, comme Googlebot Image, Googlebot Video et Googlebot News.
Comment fonctionne exactement Googlebot ?
Googlebot aide Google à fournir des résultats pertinents et précis dans les pages de résultats (SERPs).
Il le fait en parcourant les pages web, en collectant leurs données, puis en les transmettant pour qu’elles soient indexées.
Pour en savoir plus sur son fonctionnement, analysons de près les phases de crawl (exploration) et d’indexation des contenus.
Qu’est-ce que l’exploration et comment Googlebot explore-t-il le Web ?
Le crawl (ou exploration) désigne le processus par lequel des programmes automatisés, appelés crawlers, trouvent les pages web nouvelles ou mises à jour, puis les téléchargent pour les rendre accessibles dans les résultats de recherche.
La première étape du crawl s’appelle la découverte d’URL.
Avant que Google n’affiche une page dans ses résultats, il doit d’abord savoir que cette page existe.
En effet, Google est en permanence à la recherche de pages nouvelles ou actualisées.
Généralement, il découvre ces pages en suivant des liens (ou URL) depuis des pages déjà connues.
Le logiciel en charge du crawl (Googlebot) télécharge alors ces nouvelles pages. Il extrait ensuite les liens contenus sur celles-ci pour les crawler à leur tour, et le processus continue.
Googlebot s’appuie sur des algorithmes pour décider quels sites visiter, à quelle fréquence et combien de pages récupérer sur chaque site.
Qu’est-ce que le fetch et le rendu (rendering) ?
Après avoir repéré vos URL, Googlebot est passé à l’étape suivante : le fetching, c’est-à-dire le téléchargement de la page liée à l’URL.
Le fetching consiste simplement à récupérer les données servies par une URL. Mais la partie la plus intéressante est le rendu.
C’est exactement ce que fait votre navigateur web.
Le service de rendu prend la page téléchargée — généralement un mélange de fichiers HTML, CSS et JavaScript — et en fait une représentation visuelle.
Ce faisant, il exécute tout le JavaScript présent, en utilisant une version récente de Chrome.
Le rendu est crucial, car de nombreux sites utilisent JavaScript pour afficher leur contenu ou pour rendre la page plus vivante.
Sans cette étape, Google ne verrait pas ces contenus dynamiques et passerait à côté des animations, textes défilants ou autres éléments vivants.
Comment Google indexe le web ? : Bref aperçu de la phase d’indexation
Maintenant que vous savez comment Google découvre et récupère les pages web, une question essentielle se pose : comment ces pages deviennent-elles accessibles via la recherche Google ?
Eh bien, cela passe par une étape essentielle appelée l’indexation.
Une fois que Googlebot a récupéré votre contenu, il le transmet pour être analysé.
Pour faire court, l’indexation est le processus au cours duquel Google traite les informations collectées par ses robots pour cerner votre page et la classer convenablement dans son index.
Être dans l’index de Google, c’est ce qui permet à votre contenu d’être visible dans les résultats de recherche.
Notez que Google peut décider de ne pas indexer vos pages.
Quel impact sur votre SEO ?
Googlebot joue un rôle essentiel dans votre référencement naturel. Sans son passage, les pages de votre site ne seraient pas explorées et indexées (dans la plupart des cas).
Et si elles ne sont pas indexées, elles ne peuvent tout simplement pas être bien positionnées dans les résultats de recherche.
Pas de positionnement, pas de visibilité. Et donc, aucun trafic organique (non payé).
De plus, Googlebot revisite régulièrement votre site pour détecter les mises à jour ou l’ajout de nouveaux contenus.
Sans cette étape, vos modifications ne seraient pas prises en compte, ce qui complique le maintien de votre visibilité dans les résultats de recherche.
Maintenant, vous aimeriez sans doute savoir comment optimiser l’exploration de vos pages par Googlebot.
Et si nous commencions par voir comment lui indiquer où ne pas aller ? Vous y verrez plus clair dans la suite…
Comment bloquer Googlebot ?
Parfois, tu n’as pas envie que Googlebot explore ou indexe certaines parties de ton site. Que ce soit une section entière ou juste une page spécifique, il y a plusieurs raisons légitimes de vouloir poser ces limites.
Par exemple :
- Ton site est en maintenance et tu préfères éviter que les internautes tombent sur des pages incomplètes ou cassées.
- Tu veux empêcher l’indexation (et l’affichage) de fichiers comme des PDF ou des vidéos.
- Tu veux garder certaines pages privées, comme un intranet ou une page de connexion.
- Tu souhaites concentrer le crawl de Googlebot sur tes pages les plus importantes (ce qu’on appelle optimiser ton crawl budget).
Voici trois méthodes efficaces pour contrôler ce que Googlebot peut explorer :
Méthodes pour contrôler l’exploration
1. Le fichier robots.txt
Le fichier robots.txt donne des consignes aux robots explorateurs, comme Googlebot. Il leur indique quelles parties de ton site ils devraient ou ne devraient pas visiter.
C’est utile pour gérer le trafic des crawlers et peut éviter une surcharge de ton serveur.
Voici l’exemple d’un fichier robot.txt :
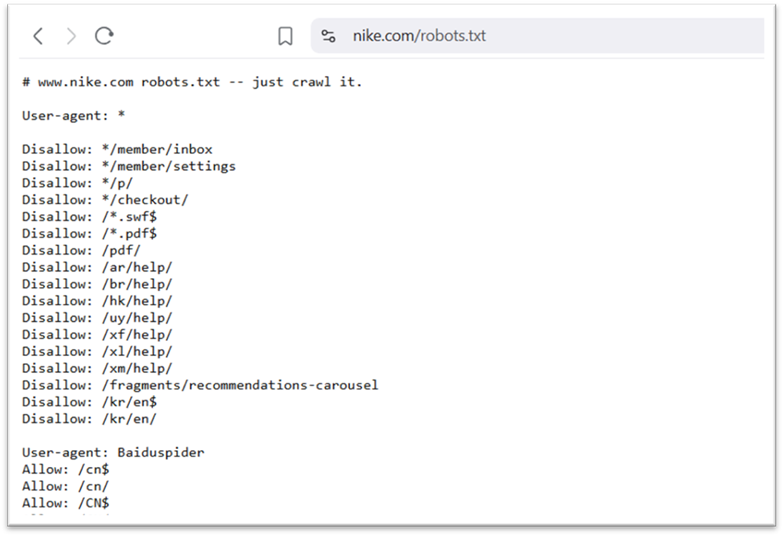
(Celui de Nike) …
Par exemple, pour bloquer l’accès à une page de connexion, tu peux ajouter cette règle :

Ceci aide à ce que les ressources de votre serveur soient focalisées sur les pages les plus importantes.
Attention cependant : même si une page est bloquée par le fichier robots.txt, elle peut quand même être indexée. Supposons que d’autres pages pointent vers elle ? Elle pourrait bien être indexée et apparaître dans les résultats de recherche.
Si tu veux vraiment qu’elle n’apparaisse pas dans les résultats, il vaut mieux utiliser une balise meta robots.
2. Les balises Meta Robots
La balise meta robots est un bout de code HTML à ajouter à celui de ta page. Elle te permet de contrôler comment cette page est explorée, indexée, et affichée dans Google.
Voici quelques exemples de balises, et leurs instructions :
- noindex : ne pas indexer la page.
- noimageindex : ne pas indexer les images de la page.
- nofollow : ne pas suivre les liens sur la page.
- nosnippet : ne pas afficher d’extrait dans les résultats de recherche.
Vous pouvez ajouter ces balises à la section <head> du code de votre page.
Exemple pour bloquer l’indexation d’une page par Googlebot :

Même si d’autres sites font un lien vers cette page, elle ne sera pas affichée dans les résultats Google.
3. La protection par mot de passe
Pour empêcher à la fois Googlebot et les utilisateurs d’accéder à une page, la méthode à utiliser est la protection par mot de passe.
Seuls les utilisateurs autorisés pourront la consulter, et Googlebot ne pourra pas l’explorer ni l’indexer.
Vous pourriez l’appliquez aux pages comme :
- Les tableaux de bord d’administration
- Les espaces membres
- Les documents internes
- Les versions de test de ton site
- Les pages de projets confidentiels
Et si une page protégée était déjà indexée, pas d’inquiétude : Google finira par la retirer de ses résultats.
Optimiser le crawl de ses pages : Définissez vous-même les actions de Googlebot
Je vous recommande bien-sûr d’exploiter les méthodes abordées plus tôt pour contrôler l’exploration de Googlebot, votre budget de crawl etc. mais, veillez aussi à ne pas en être victime.
Evitez, par exemple, de bloquer l’accès à une page importante à l’aide d’un mot de passe. Googlebot ne pourrait tout simplement pas y accéder.
Et mettre tout votre site en noindex ? Mauvaise idée si vous voulez des pages indexées et capables d’attirer du trafic.
Les méthodes fournies précédemment vous aideront sans doute à mieux contrôler l’activité de Googlebot sur votre site. Mais n’hésitez pas non plus à vous servir de ces connaissances pour identifier d’éventuelles anomalies, selon vos besoins en matière d’indexation.
Comment contrôler les activités de Googlebot sur mon site ?
…Identifier les visites de Googlebot et en tirer profit pour le SEO
Surveiller régulièrement le comportement de Googlebot vous permet de repérer rapidement d’éventuels problèmes de crawl ou d’indexation, et d’intervenir avant que cela n’affecte votre visibilité naturelle.
Voici deux méthodes efficaces pour garder un œil sur ses passages.
1. Surveiller les statistiques d’exploration via la Search Console
Google Search Console fournit un rapport dédié aux statistiques de crawl, très utile pour analyser les activités de Googlebot sur votre site.
Pour y accéder, connectez-vous à votre compte GSC, puis rendez-vous dans “Paramètres” via le menu à gauche.
Dans la section “Exploration”, cliquez sur “Afficher le rapport”.
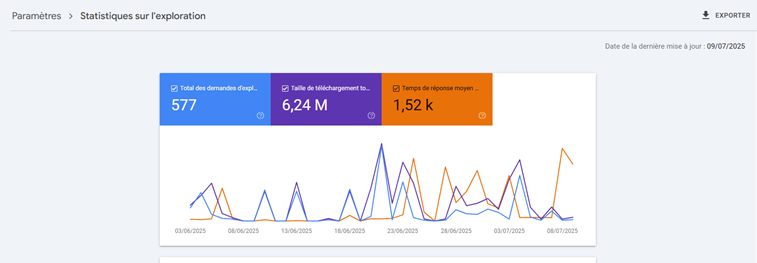
Vous y trouverez trois graphiques illustrant l’évolution de plusieurs indicateurs sur les trois derniers mois :
- Nombre total de requêtes d’exploration : correspond aux visites de Googlebot sur votre site.
- Volume total de données téléchargées : indique la quantité de contenu récupérée.
- Temps moyen de réponse : montre le délai de réaction de votre serveur face aux requêtes.
🔎 Soyez attentif aux pics, baisses brutales ou tendances inhabituelles. Et collaborez avec votre développeur si vous remarquez des anomalies (ex : erreurs serveur, ralentissements, changement de structure…).
Vous trouverez aussi une section de détail des demandes d’exploration.
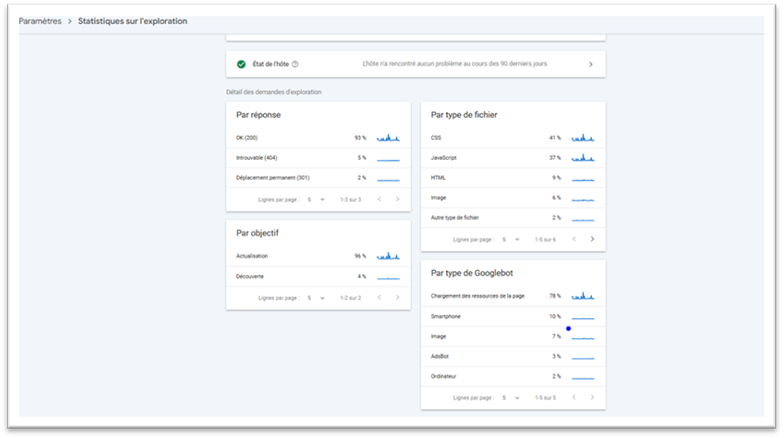
Elle présente les données selon plusieurs critères :
- Par code de réponse : utile pour savoir si votre site répond correctement aux requêtes. Un grand nombre de statuts “200 OK” est un bon signe. En revanche, des erreurs comme 404 (page introuvable) ou 301 (redirection) peuvent signaler des liens cassés ou du contenu déplacé.
- Par type de fichier : indique quels types de fichiers sont explorés (HTML, images, scripts…). Pratique pour détecter des problèmes spécifiques.
- Par objectif : identifie l’intention derrière chaque exploration. Un taux élevé de “découverte” signifie que Google recherche de nouvelles pages ; un taux élevé de “rafraîchissement” indique qu’il revisite du contenu existant.
- Par type de Googlebot : vous informe sur les agents utilisateurs (user agents) en activité. Si vous constatez une hausse soudaine de crawl, ce filtre peut vous aider à comprendre qui est à l’origine de ces pics.
2. Utiliser les fichiers journaux (logs)
Les fichiers journaux enregistrent toutes les requêtes faites à votre serveur : visiteurs, navigateurs, bots…
Ils permettent de suivre en détail le passage de Googlebot et d’identifier certaines anomalies.
Voici ce que vous pouvez extraire d’un log :
- L’adresse IP des « visiteurs »
- L’heure de chaque requête
- L’URL demandée
- Le type de requête
- Le volume de données transférées
- Le user agent
C’est une vraie mine d’or pour savoir quand, comment, et à quelle fréquence Googlebot parcourt votre site. Vous pouvez aussi y détecter d’éventuels ralentissements ou erreurs de chargement.
Où trouver ces fichiers ?
Les fichiers logs sont stockés sur votre serveur d’hébergement. Pour y accéder :
- Utilisez le gestionnaire de fichiers proposé par votre hébergeur (beaucoup en proposent un).
- Sinon, un développeur ou un technicien web peut les récupérer via un client FTP comme FileZilla.
Est-ce bien Googlebot qui explore votre site ?
Certains outils SEO ou robots malveillants peuvent se faire passer pour Googlebot. Cela leur permet parfois de contourner les restrictions mises en place pour bloquer certains accès.
Alors, si vous avez des doutes sur des activités suspectes sur votre site, sachez qu’il est possible de vérifier si le robot qui interagit avec votre serveur est bien un vrai Googlebot.
Autrefois, cette vérification passait uniquement par une requête DNS. Mais aujourd’hui, Google simplifie la tâche en rendant publiques les adresses IP utilisées par ses robots, que vous pouvez comparer aux logs de votre serveur.
Deux méthodes fiables existent donc pour effectuer cette vérification :
✔️ Méthode 1 : La vérification manuelle (idéal pour des cas isolés)
Si vous souhaitez faire une vérification ponctuelle, vous pouvez utiliser des outils en ligne de commande. C’est largement suffisant dans la majorité des cas.
Étapes à suivre :
- Lancez une résolution DNS inverse à l’aide de la commande host, en ciblant l’adresse IP présente dans vos journaux serveur.
- Vérifiez que le nom de domaine retourné appartient bien à Google : il doit se terminer par googlebot.com, google.com ou googleusercontent.com.
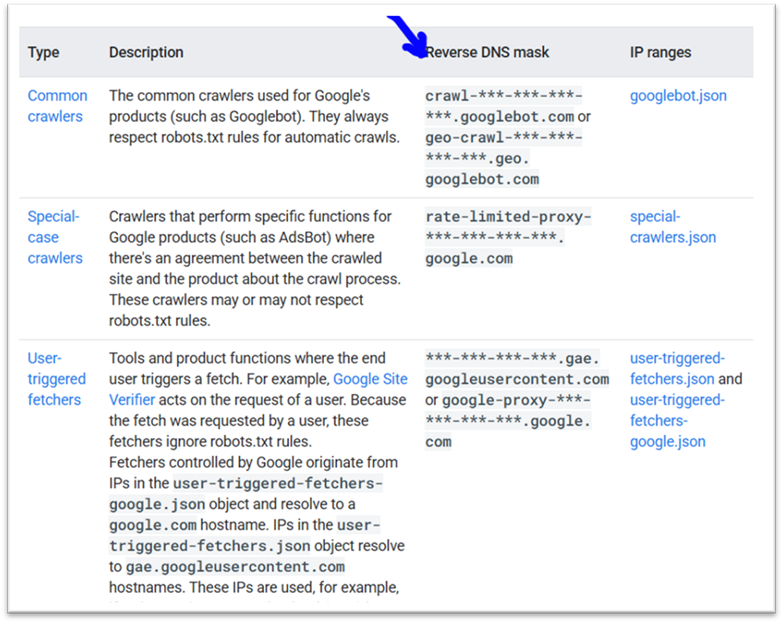
- Ensuite, effectuez une résolution DNS directe sur ce nom de domaine, toujours avec la commande host.
- Comparez le résultat avec l’adresse IP d’origine : si les deux correspondent, c’est bon signe.
Exemple :
1-)
host 35.247.243.240
→ … geo-crawl-35-247-243-240.geo.googlebot.com
2-)
host geo-crawl-35-247-243-240.geo.googlebot.com
→ 35.247.243.240 ✅
✔️ Méthode 2 : La vérification automatique (plus adaptée à une surveillance générale)
Vous pouvez aussi automatiser cette vérification. Il suffit de faire correspondre l’adresse IP détectée avec les plages d’IP officielles de Google, disponibles publiquement.
Ces listes couvrent différents types de robots :
- Les crawlers classiques comme Googlebot
- Les robots spécifiques comme AdsBot
- Les extractions initiées par les utilisateurs (utilisateurs mêmes ou Google)
💡 Remarque : dans les fichiers JSON fournis par Google, les IP sont listées au format CIDR.
Vous trouverez plus de précisions sur ces méthodes dans les pages officielles de Google.
L’User-Agent (Googlebot) met un point d’honneur à l’expérience utilisateur ?
Optimiser son site pour le robot de Google peut aussi vouloir dire : l’optimiser du point de vue de l’UX.
Nous l’avons vu, faire crawler sa page n’est pas une garantie d’indexation.
Par exemple, les pages de faible qualité ou offrant une mauvaise expérience utilisateur risquent de ne pas être indexées.
Pensez non seulement au contenu, mais aussi aux performances techniques de vos pages.
Et en passant, prenez grand soin de leur version mobile : comme mentionné en début d’article, Google dispose d’un bot dédié à cette version de votre site.
📌 Note : En fait, d’après la documentation officielle de Google, pour la majorité des sites, c’est la version mobile du contenu qui est principalement indexée.
En conséquence, après demandes d’exploration Googlebot, la plupart des visites seront effectuées par le robot mobile, tandis que le robot pour ordinateur est beaucoup moins sollicité beaucoup moins.
Vous ne voudriez pas prendre le risque d’être mal vu par Googlebot Smartphone… Si ?! Haha…
Pourquoi est-il essentiel de rendre son site « optimisé » pour Googlebot ?
De manière générale, un site optimisé pour Googlebot vous permet simplement de :
Contrôler votre budget de crawl :
Comme vu plus haut, cela permet à Googlebot de consacrer son temps d’exploration aux pages qui comptent vraiment.
Être indexé :
Autrement dit, faire apparaître vos pages importantes dans les résultats de recherche.